Part 6 - A simple HTTP parser in python
(The changes introduced in this post start here.)
Let’s implement our own little HTTP request parser, such that we’re not reliant on 3rd party libraries and gain some more understanding about the HTTP message format. We’ll just shamelessly copy the flow of the httptools.HttpRequestParser, so that we can just drop our replacement in without any other changes required to our code.
The general plan
As you can see in this image from MDN, the message structure is quite rigid and there are not a lot of rules necessary to implement a simple parser.
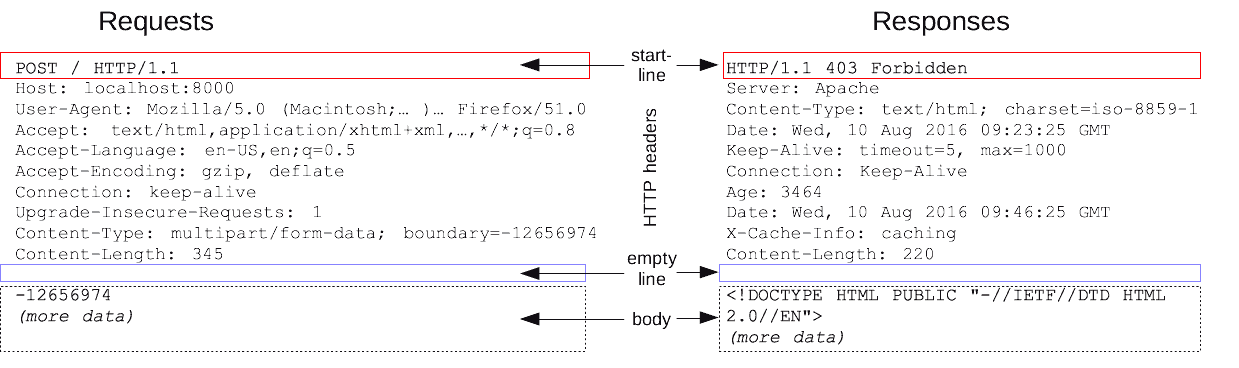
The first line is always the start line with a fixed number of positional arguments (HTTP method, request url/path, HTTP version) delimited by whitespace. Each following line is a Name: Value header pair until an eventual empty line. If there is a Content-Length header, then after the empty line you must also expect a message body of the specified length.
So by splitting on lines and parsing the information of every line, while keeping track of where in the message structure we currently are, we can parse out the information step-by-step. One wrinkle that slightly complicates the issue is that the data can potentially come in as many sequential chunks. So we always need to be aware of that the current line we’re looking at might not yet be completely received.
For example, instead of receiving the following request in a single chunk.
b"GET /index.html HTTP/1.1\r\nHost: localhost:5000\r\nUser-Agent: curl/7.69.1\r\nAccept: */*\r\n\r\n"We may instead receive several, sequential chunks like so:
b"GET /index.html "
b"HTTP/1.1\r\nHost"
b": localhost:5000"
b"\r\nUser-Agent: "
b"curl/7.69.1\r\nA"
b"ccept: */*\r\n\r"
b"\n"An httptools inspired implementation
Let’s first create a new file splitbuffer.py where we’ll implement a simple buffer utility class. It should be possible to continuously feed data into it and then pop elements out of it based on a separator.
#./splitbuffer.py
class SplitBuffer:
def __init__(self):
self.data = b""
def feed_data(self, data: bytes):
self.data += data
def pop(self, separator: bytes):
first, *rest = self.data.split(separator, maxsplit=1)
# no split was possible
if not rest:
return None
else:
self.data = separator.join(rest)
return first
def flush(self):
temp = self.data
self.data = b""
return tempHere is a little example of how it would work.
>>> buffer = SplitBuffer()
>>> buffer.feed_data(b"abc,")
>>> buffer.feed_data(b"defg")
>>> buffer.feed_data(b",hi,")
>>> assert buffer.pop(separator=b",") == b"abc"
>>> assert buffer.pop(separator=b",") == b"defg"
>>> buffer.feed_data(b",jkl")
>>> assert buffer.pop(separator=b",") == b"hi"
>>> assert buffer.pop(separator=b",") == b""
>>> assert buffer.pop(separator=b",") is None
>>> assert buffer.flush() == b"jkl"We’ll use the .pop behavior while we’re in the start/headers part of the message (where entries are separated by newlines) and we’ll use the .flush behavior while grabbing the body (which should not be separated at all, just consumed as is).
In a new file http_parse.py we can now implement our own little HTTP parser.
#./http_parse.py
from splitbuffer import SplitBuffer
class HttpRequestParser:
def __init__(self, protocol):
self.protocol = protocol
self.buffer = SplitBuffer()
self.done_parsing_start = False
self.done_parsing_headers = False
self.expected_body_length = 0
def feed_data(self, data: bytes):
self.buffer.feed_data(data)
self.parse()
def parse(self):
if not self.done_parsing_start:
self.parse_startline()
elif not self.done_parsing_headers:
self.parse_headerline()
elif self.expected_body_length:
data = self.buffer.flush()
self.expected_body_length -= len(data)
self.protocol.on_body(data)
self.parse()
else:
self.protocol.on_message_complete()
def parse_startline(self):
line = self.buffer.pop(separator=b"\r\n")
if line is not None:
http_method, url, http_version = line.strip().split()
self.done_parsing_start = True
self.protocol.on_url(url)
self.parse()
def parse_headerline(self):
line = self.buffer.pop(separator=b"\r\n")
if line is not None:
if line:
name, value = line.strip().split(b": ", maxsplit=1)
if name.lower() == b"content-length":
self.expected_body_length = int(value.decode("utf-8"))
self.protocol.on_header(name, value)
else:
self.done_parsing_headers = True
self.parse()We use 2 flags self.done_parsing_start and self.done_parsing_headers to keep track of whether we’ve already parsed the start line or the headers, respectively. If we encounter a Content-Length header while parsing the headers we’ll set the self.expected_body_length so that we know how much body we have left to read before the message is over. The most important part is the parse() method which tries to continuously parse out the next thing (start line, header line, a chunk of the body) from the raw data coming in through feed_data().
The parser takes a protocol input on instantiation which expects the exact same callbacks to be implemented as httptools.HttpRequestParser does. So, in order to start using our own parser instead of httptools we only need to replace the import in server.py.
#./server.py
@@ -1,7 +1,7 @@
from typing import Tuple
import socket
import threading
- from httptools import HttpRequestParser
+ from http_parse import HttpRequestParser
from http_request import HttpRequestParserProtocol
from http_response import make_response
Notes
Of course, there is basically no error handling, no checking for a correct format, etc. We’re just assuming that the client will send a well-formed HTTP request, otherwise everything will break. But I think that’s fine, we just want to see how all the basic pieces fit together and not get bogged down in trying to handle all corner cases.
Also, to emphasize this point again, the message structure we’ve looked at here is HTTP/1.1. HTTP/2 has a somewhat different way of formatting the messages. If you want to read more about that, check here.
Now we can be very proud of ourselves to have reinvented the wheel here. It has resulted in a far slower and buggier version of what httptools already provides. Great job. The next step in this series will be to finally, actually implement our very own WSGI server.